Let's start. Let's learn about KV Caching, how a simple observation and a rather simple implementation can get you 5x speedup on autoregressive token generation in attention based models. Let's also implement this using mlx, comparing a naive autoregressive loop implementation against a cached one.
To understand KV Cache, let's backtrack and understand what are Keys and what are Values, why would be a need to store these values arise, what are the trade offs (there is always a trade off).
I'm assuming who is reading this is familiar with basic attention mechanism and right now let's only focus on self-attention, also in my implementations later, I will ignore attention masks, position embeddings etc which are necessary for large language models but not so much to demonstrate the use of KV Caching.
Attention Please!
Okay let's jump right in and let me spoil right away where we are saving computation by trading for a higher memory, the the region of interest for us is where we calculate these Query, Key and Value matrices from input using corresponding weight matrices Wq, Wk, and Wv and to spoil things even more we don't have to 1) calculate all queries for every new token to predict (only latest is enough) and 2) calculate all keys and value matrices (we can save all previous keys and value matrices, only calculate the latest ones and then save). Now let's look at some diagrams and later some code in mlx to understand things at a lower level.
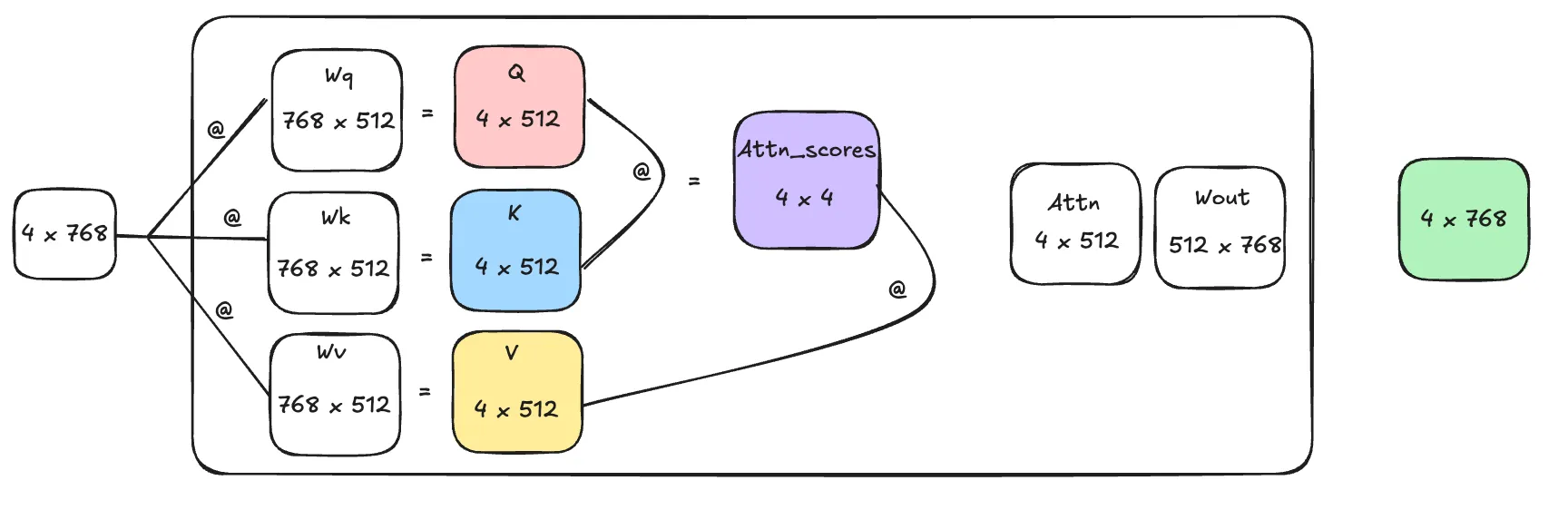
On a high level this is what happens in the attention block. @ denotes matrix multiplication here. We start with a input of dimension 4x768 which is then projected to a different dimension of three different matrices called Query, Key and Values. Queries and Keys are used to calculate attention scores, which contains information about the "relevancy" of each token with respect to another. Then we use these attention scores to modify the Value matrix and using Wout we project it to out the same dimension with which it arrives, but now since these tokens interacted with all other tokens (using dot products and scoring each other and such) this matrix now contains information about each other and this chunk of tokens as a whole.
Like I said before we're saving computation at forming the matrices Q, K and V. In the diagram I've used 4 tokens and an embedding size of 768 as example but imagine if the context is 100K tokens and embedding dimension is 2048, each matrix multiplication is massive, and this operation happens many times, since these LLMs are stacked attention blocks with 80 layers deep or so sometimes, computation becomes massive.
# you can calculate your model's theoretical cache size by
theoretical_cache_size = (
n_layers * # number of attention layers in the model
2 * # keys, values
b * # batch_size
seq_len * # context length
n_heads * # number of heads
head_dim * # dimension of each head
4 # float32 - 4 bytes, float16 - 2 bytes, ...
) # bytes
Autoregressive Token Generation
Now let's get a bit lower level and understand how these models generate each token, one after another by looking closely at Q, K and V Matrices.
First let's start with a naive generation loop and we can easily find out where the optimization comes from.
Step 1

Let's take a sentence "A mysterious letter arrived", after passing through a bunch of transformer layers we get the output matrix which in the image above is of 4 x 7 dimension and to predict the next token we choose the embeddings corresponding to the last token "arrived" and project it to vocab size using a mlp layer and we get probabilities over which token to pick next and we sample over that probabilities to pick the next token, in this case it's "in". Now let's generate the next token.
Step 2

To generate the next token, what we do is simply append the token for "in" to the input tokens ("A mysterious letter arrived") and now the current input is ("A mysterious letter arrived in") and given this input, the model will predict the next token. Now you can see the Q, K and V matrices have one additional row/column corresponding to the new token "in" and attention matrix is of size 5x5 now, instead earlier it was 4x4. Then for the next prediction we pick the output embedding corresponding to the token "in" and get probabilities over next token and sample the next token, which in this case is "mail". Crucially, notice that in this second step, we recalculated the Q, K, and V values for the first four tokens ("A mysterious letter arrived") even though those values have not changed since Step 1. This is the massive, repeated computation we will optimize later.
Okay, let's write some code for this simple generation loop in mlx and later observe the savings.
Transformer Implementation:
# Transformer.py
import mlx.core as mx
import mlx.nn as nn
class Attention(nn.Module):
def __init__(self, config):
super().__init__()
self.q_proj = nn.Linear(config.dim, config.dim)
self.k_proj = nn.Linear(config.dim, config.dim)
self.v_proj = nn.Linear(config.dim, config.dim)
self.out_proj = nn.Linear(config.dim, config.dim)
self.heads = config.n_heads
self.dim_per_head = config.dim // config.n_heads
self.scale = self.dim_per_head ** -0.5
def __call__(self, x):
queries = self.q_proj(x)
keys = self.k_proj(x)
values = self.v_proj(x)
batch_size, seq_len, _ = x.shape
queries = queries.reshape(batch_size, seq_len, self.heads, self.dim_per_head).transpose(0, 2, 1, 3)
keys = keys.reshape(batch_size, seq_len, self.heads, self.dim_per_head).transpose(0, 2, 1, 3)
values = values.reshape(batch_size, seq_len, self.heads, self.dim_per_head).transpose(0, 2, 1, 3)
attn = mx.matmul(queries, keys.transpose(0, 1, 3, 2)) * self.scale
attn_scores = mx.softmax(attn, axis=-1) # (B, H, seq_len, seq_len)
x = mx.matmul(attn_scores, values).reshape(batch_size, seq_len, -1)
x = self.out_proj(x)
return x
class TransformerBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.attn = Attention(config)
self.mlp = MLP(config)
self.input_layernorm = nn.RMSNorm(config.dim)
self.post_attention_layernorm = nn.RMSNorm(config.dim)
def __call__(self, x):
r = self.attn(self.input_layernorm(x))
h = r + x
r = self.mlp(self.post_attention_layernorm(h))
out = r + h
return out
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.dim = config.dim
self.hidden_dim = config.mlp_hidden_size
self.layer1 = nn.Linear(self.dim, self.hidden_dim)
self.layer2 = nn.Linear(self.hidden_dim, self.dim)
def __call__(self, x):
return self.layer2(nn.silu(self.layer1(x)))
class MiniTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.embed = nn.Embedding(config.vocab_size, config.dim)
self.layers = [
TransformerBlock(config) for _ in range(config.n_layers)
]
self.lm_head = nn.Linear(config.dim, config.vocab_size)
def __call__(self, x):
z = self.embed(x)
for layer in self.layers:
z = layer(z)
logits = self.lm_head(z)
return logits
@property
def attn_layers(self):
return self.layers
if __name__ == "__main__":
config = Config()
breakpoint()
x = mx.array([[1, 2, 3, 4]])
decoder = MiniTransformer(config)
out = decoder(x)
print(out.shape)
Generation Loop:
import mlx.core as mx
def generate_step(
prompt,
model,
**kwargs
):
max_tokens = kwargs["max_tokens"]
input = prompt
for _ in range(max_tokens):
logits = model(input)
logit = logits[:, -1, :]
probs = mx.softmax(logit)
next_token = mx.argmax(probs)
yield next_token.item()
next_token = mx.expand_dims(mx.array(next_token), (0, 1))
input = mx.concatenate([input, next_token], axis=-1)
def naive_generate(
model,
prompt,
max_tokens,
**kwargs,
):
kwargs["max_tokens"] = max_tokens
token_generator = generate_step(prompt, model, **kwargs)
for _, text in enumerate(token_generator):
yield text
Everything I've explained above about obtaining logits from the model, using the latest token, obtaining probabilities over the next token and sampling the next token (greedy sampling in my case), is implemented here.
KV Cache Optimization
Now let's take a closer look. Does the fact that we use only the embeddings of the latest token to produce a new token give us some clues about unwanted computation?

Observation 1: If we backtrack and observe the embeddings that we want from the output matrix, which is the embeddings corresponding to the latest token "in" is obtained, we can see that it is obtained from the last row of attn matrix, which is itself obtained from last row of the query matrix, that means we're essentially wastefully computing the full Q matrix for tokens ("A mysterious letter arrived") which is clearly unnecessary.
Observation 2: Another observation is that if you compare the first two figures for generating token "in" and token "main", we if focus on K and V matrices, we are calculating K and V matrices for ("A", "mysterious", "letter", "arrived") for generating token "in" and ("A", "mysterious", "letter", "arrived", "in") for generating the next token "mail", and you can see that for every new token generation we are wastefully computing K and V matrices from the beginning over and over again (in this case for tokens ("A", "mysterious", "letter", "arrived"). Now this is redundant, what if everytime we calculate these K and V values, keep them saved and only generate K and V for the latest token and append that to previously saved K and V to proceed with attention computation.
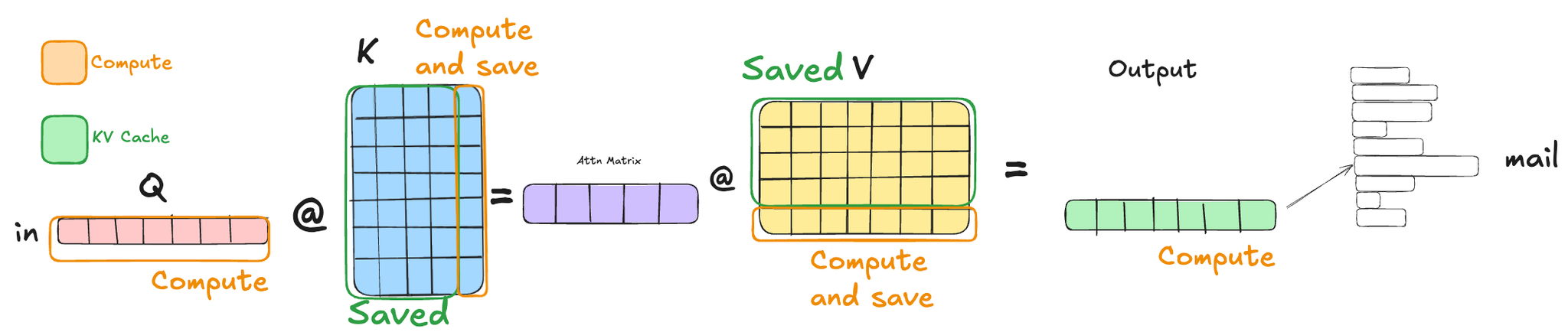
You can see from the diagram above, since we only need the embedding information of the latest token "in" to predict the next token we compute 1.) Q values only for that token, 2.) We compute K and V values for that token and append saved KV value for previous tokens. This way as the context length for the next token generation increases we're not bottlenecked by computation since we're essentially computing these only one token at a time.
Computationally while calculating Q @ K, we're reducing from (L x D @ D x L) → (1 x D @ D x L) and at attn_scores @ V we're reducing from (L x L @ L x D) → (1 x L @ L x D), along with, while computing K, V from inputs, we're reducing from (L x D' @ D' x D) → (1 x D' @ D' x D).
Implementing KV Cache using MLX
Cache Implementation:
import mlx.core as mx
class _BaseCache:
@property
def state(self):
return (None, None)
@state.setter
def state(self, v):
if v is not None and v:
raise ValueError("This cache has not state but state was set")
class NaiveKVCache(_BaseCache):
def __init__(self):
self.keys = None
self.values = None
def update_and_fetch(self, keys, values):
if self.keys is None or self.values is None:
self.keys = keys
self.values = values
else:
self.keys = mx.concatenate([self.keys, keys], axis=2)
self.values = mx.concatenate([self.values, values], axis=2)
return self.keys, self.values
@property
def state(self):
return self.keys, self.values
@state.setter
def state(self, v):
self.keys, self.values = v
Attention Implementation:
import mlx.core as mx
import mlx.nn as nn
from llms.kv_cache.cache import NaiveKVCache
class Config:
dim = 256
n_layers = 4
n_heads = 4
mlp_hidden_size = 4 * 256
vocab_size = 1000
max_seq_len = 128
class Attention(nn.Module):
def __init__(self, config):
super().__init__()
self.q_proj = nn.Linear(config.dim, config.dim)
self.k_proj = nn.Linear(config.dim, config.dim)
self.v_proj = nn.Linear(config.dim, config.dim)
self.out_proj = nn.Linear(config.dim, config.dim)
self.heads = config.n_heads
self.dim_per_head = config.dim // config.n_heads
self.scale = self.dim_per_head ** -0.5
def __call__(self, x, cache=None):
queries = self.q_proj(x)
keys = self.k_proj(x)
values = self.v_proj(x)
batch_size, seq_len, _ = x.shape
queries = queries.reshape(batch_size, seq_len, self.heads, self.dim_per_head).transpose(0, 2, 1, 3)
keys = keys.reshape(batch_size, seq_len, self.heads, self.dim_per_head).transpose(0, 2, 1, 3)
values = values.reshape(batch_size, seq_len, self.heads, self.dim_per_head).transpose(0, 2, 1, 3)
if cache is not None:
keys, values = cache.update_and_fetch(keys, values)
attn = mx.matmul(queries, keys.transpose(0, 1, 3, 2)) * self.scale
attn_scores = mx.softmax(attn, axis=-1) # (B, H, seq_len, seq_len)
x = mx.matmul(attn_scores, values).reshape(batch_size, seq_len, -1)
x = self.out_proj(x)
return x
class TransformerBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.attn = Attention(config)
self.mlp = MLP(config)
self.input_layernorm = nn.RMSNorm(config.dim)
self.post_attention_layernorm = nn.RMSNorm(config.dim)
def __call__(self, x, cache=None):
r = self.attn(self.input_layernorm(x), cache=cache)
h = r + x
r = self.mlp(self.post_attention_layernorm(h))
out = r + h
return out
class MiniTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.embed = nn.Embedding(config.vocab_size, config.dim)
self.layers = [
TransformerBlock(config) for _ in range(config.n_layers)
]
self.lm_head = nn.Linear(config.dim, config.vocab_size)
def __call__(self, x, caches=None):
z = self.embed(x)
if caches is None:
caches = [None] * len(self.layers)
for layer, cache in zip(self.layers, caches):
z = layer(z, cache)
logits = self.lm_head(z)
return logits
@property
def attn_layers(self):
return self.layers
def make_cache(self):
return [
NaiveKVCache()
for _ in self.attn_layers
]
Generation Loop:
def naive_cached_generate(
model,
prompt,
max_tokens,
caches,
**kwargs,
):
# Prefill Stage
total_tokens = prompt.shape[-1]
processed_tokens = 0
tokens_per_step = 32
def _step(input_tokens):
logits = model(input_tokens)
logit = logits[:, -1, :]
probs = mx.softmax(logit)
# greedy sampling
next_token = mx.argmax(probs)
return next_token
while total_tokens - processed_tokens > 1:
rem_tokens_to_fill = (total_tokens - processed_tokens) - 1
num_tokens = min(tokens_per_step, rem_tokens_to_fill)
current_tokens = prompt[:, :num_tokens]
# These tokens k and v values get prefilled in
# respective transformer blocks cache
model(current_tokens, caches)
mx.eval([c.state for c in caches])
processed_tokens += num_tokens
prompt = prompt[:, num_tokens:]
mx.clear_cache()
# Decoding Starts
# This leaves us with one token (in user prompt)
# from which we can start to predict next token
next_token = _step(prompt)
# First token predicted from the user prompt
# Subsequent predictions, one token at a time, cache has previous history
mx.async_eval(next_token)
for i in range(max_tokens):
if i % 256 == 0:
mx.clear_cache()
next_y = _step(next_token[None][None])
mx.async_eval(next_y)
yield next_token.item()
next_token = next_y
This implementation has a naive KV cache implementation, this setup has very minor changes to the model
- The
make_cachefunction, returns cache objects per transformer layer, which we can package and pass corresponding cache object along with the layer to ensuring that each layer stores its own KV values from the tokens - Inside the Attention block, we use
cache.update_and_fetch(keys, values). This function is responsible for (a) saving the newly computedKandVfor the current token, and (b) returning the concatenated tensor of all previous and currentKandVto be used in the dot product with the query.
MLX Lazy Evaluation: Are you surprised by this mx.async_eval and mx.eval in the implementation. Look up lazy evaluation in mlx. It's very cool, so for any operation
y = fun(x)the function is not actually executed and y doesn't have a value yet, a computation graph is built and that's it. It is executed only whenevalis called on the value, or if we print the value, if we saving the value or calling.item()on the array.
Prefill and Decode
The other interesting thing at the generation loop using caches is, we can divide the generation phase into two stages. Prefill and Decode.
Once the user provides a prompt which contains n tokens, we can prefill the cache with KV values of these tokens and since we are not restricted with autoregression here, we can process and save KVs for bunch of tokens at once.
Once we prefill the cache for n-1 tokens, we use that last token to start the decoding process where the autoregressive nature kicks in and as each token is passed through the model it gets saved in the cache objects and for next generation, we will only need the latest generated token to generate the next one.
You can observe this prefill and decode stages in the naive_cached_generate function.
Performance
Token Generation Speed:
import time
from functools import partial
import mlx.core as mx
from llms.kv_cache.generate import naive_generate, naive_cached_generate
from llms.kv_cache.transformer import Config, MiniTransformer
def measure_model_performance(use_cache=True):
config = Config()
model = MiniTransformer(config)
max_tokens = 128
token_generator = None
if use_cache:
token_generator = partial(
naive_cached_generate,
model,
max_tokens=max_tokens,
)
else:
token_generator = partial(
naive_generate,
model,
max_tokens=max_tokens
)
times = []
for i in range(20):
start = time.perf_counter()
prompt = mx.random.randint(0, 100, (1, 80))
caches = None
if use_cache:
caches = model.make_cache()
for out in token_generator(prompt=prompt, caches=caches):
pass
# print(out, flush=True, end=" ")
end = time.perf_counter()
if i > 2:
times.append(end-start)
return times
def main():
naive_times = measure_model_performance(use_cache=False)
print(f"Generation Time Without KV Cache: {mx.array(naive_times).mean().item()}")
cached_times = measure_model_performance(use_cache=True)
print(f"Generation Time KV Cache: {mx.array(cached_times).mean().item()}")
if __name__ == "__main__":
main()
Generation Time Without KV Cache: 0.183353s
Generation Time KV Cache: 0.037206
Speedup: 4.928026138343503x, on M3 Pro Macbook
5x improvement over a very naive implementation is not bad, there are a bunch of other optimizations we can do in caching implementation, the literature goes so deep with variants like QuantizedCache for improving memory, SlidingWindowCache for managing large context sizes, PagedAttention, Cross-Layer KV Sharing, KV Cache Eviction Policies with Multi Query Attention (MQA), Grouped Query Attention (GQA), Sliding Window Attention, Speculative Decoding etc. Let's keep going!
MLX async eval:
# Another neat trick I observed is that with the way I wrote the last for loop
# for predicting max tokens in the decoding stage of cached generation.
# The first loop I wrote is this:
for i in range(max_tokens):
yield next_token.item()
if i % 256 == 0:
mx.clear_cache()
next_token = _step(next_token[None][None])
mx.async_eval(next_token)
# The current loop as you can see is:
mx.async_eval(next_token)
for i in range(max_tokens):
if i % 256 == 0:
mx.clear_cache()
next_y = _step(next_token[None][None])
mx.async_eval(next_y)
yield next_token.item()
next_token = next_y
# The bottom loop has 2x speedup compared to the top one,
# That is because processes overlap between async_eval and yield in the faster
# loop, whereas there is no overlap in the first for loop.
References